
Только что мы изучили задачу классификации, относящуюся к стратегии "обучение с учителем".
В этой части лекции мы введем понятия кластеризации, кластера, кратко рассмотрим классы методов, с помощью которых решается задача кластеризации, некоторые моменты процесса кластеризации, а также разберем примеры применения кластерного анализа.
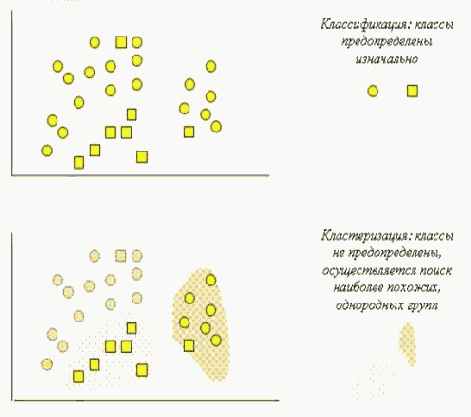
Задача кластеризации сходна с задачей классификации, является ее логическим продолжением, но ее отличие в том, что классы изучаемого набора данных заранее не предопределены.
Синонимами термина "кластеризация" являются "автоматическая классификация", "обучение без учителя" и "таксономия".
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Цель кластеризации - поиск существующих структур.
Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных".
Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер (cluster) как "скопление", "гроздь".
Кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
• внутренняя однородность;
• внешняя изолированность.
Вопрос, задаваемый аналитиками при решении многих задач, состоит в том, как организовать данные в наглядные структуры, т.е. развернуть таксономии.
Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явлений.
В таблице 5. 2 приведено сравнение некоторых параметров задач классификации и кластеризации.

На рис. 5. 7 схематически представлены задачи классификации и кластеризации.
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping) [22]. Схематическое изображение непересекающихся и пересекающихся кластеров дано на рис. 5.8.
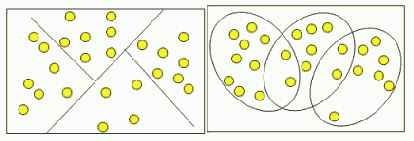
Рис. 5.8. Непересекающиеся и пересекающиеся кластеры
Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д., а некоторые методы могут создавать кластеры произвольной формы.
Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных) либо предполагать в наборе данных наличие кластеров различного размера.
Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее.
В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма.
Данные особенности следует учитывать при выборе метода кластеризации.
Подробнее обо всех свойствах кластерного анализа будет рассказано в лекции, посвященной его методам.
На сегодняшний день разработано более сотни различных алгоритмов кластеризации. Некоторые, наиболее часто используемые, будут подробно описаны во втором разделе курса лекций.
Приведем краткую характеристику подходов к кластеризации [21].
Алгоритмы, основанные на разделении данных (Partitioning algorithms), в т.ч. итеративные:
разделение объектов на k кластеров;
итеративное перераспределение объектов для улучшения кластеризации.
Иерархические алгоритмы (Hierarchy algorithms):
агломерация: каждый объект первоначально является кластером, кластеры, соединяясь друг с другом, формируют больший кластер и т.д.
Методы, основанные на концентрации объектов (Density-based methods):
основаны на возможности соединения объектов;
игнорируют шумы, нахождение кластеров произвольной формы.
Грид-методы (Grid-based methods):
квантование объектов в грид-структуры.
Модельные методы (Model-based): использование модели для нахождения кластеров, наиболее соответствующих данным.