Подгонка параметров распределения
Как и в процедуре, описанной в главе 3, по поиску оптимального f при нормальном распределении, мы должны преобразовать необработанные торговые данные в стандартные единицы. Сначала мы вычтем среднее из каждой сделки, а затем разделим полученное значение на стандартное отклонение. Далее мы будем работать с данными в стандартных единицах. После того как мы приведем сделки к стандартным значениям, можно отсортировать их в порядке возрастания. На основе полученных данных мы сможем провести тест К-С. Нашей целью является поиск таких значений LOC, SCALE, SKEW и KURT, которые наилучшим образом подходят для фактического распределения сделок. Для определения «наилучшего приближения» мы полагаемся на тест К-С. Рассчитаем значения параметров, используя «метод грубой силы двадцатого века». Мы просчитаем каждую комбинацию для KURT от 3 до 0,5 с шагом -0,1 (мы можем также взять интервал от 0,5 до 3 с шагом 0,1, так как направление не имеет значения). Далее просчитаем каждую комбинацию для SCALE от 3 до 0,5 с шагом -0,1. Пока оставим LOC и SKEW равными 0. Таким образом, нам надо обработать следующие комбинации:

Для каждой комбинации проведем тест К-С. Комбинацию, которая даст наименьшую статистику К-С, будем считать оптимальной для параметров SKALE и KURT (на данный момент). Чтобы провести тест К-С для каждой комбинации, нам необходимо как фактическое распределение, так и теоретическое распределение (определяемое параметрами тестируемого характеристического распределения).
Мы уже знаем, как создать функцию распределения вероятности X/N, где N является общим числом сделок, а Х является рангом (от 1 до N) данной сделки.
Теперь нам надо рассчитать ФРВ для теоретического распределения при данных значениях параметров LOC, SCALE, SKEW и KURT. У нас есть характеристическая функция регулируемого распределения, она задается уравнением (4.06). Чтобы получить ФРВ из характеристической функции, необходимо найти интеграл характеристической функции. Мы обозначаем интеграл, т.е. площадь под кривой характеристической функции в точке X, как N(X).
Таким образом, так как уравнение (4.06) дает первую производную интеграла, мы обозначим уравнение (4.06) как N'(X). В большинстве случаев вы не сможете вывести интеграл функции, даже если вы опытный математик. Поэтому вместо интегрирования функции (4.06) мы будем использовать другой метод. Этот метод потребует больших усилий, но он применим к любой функции.
Вероятность для любой точки на графике характеристической функции можно оценить, если распределение представить себе как последовательность узких прямоугольников. Тогда для любого данного прямоугольника в распределении вы можете рассчитать вероятность, ассоциированную с этим прямоугольником, как отношение суммы площадей всех прямоугольников слева от вашего прямоугольника (включая площадь вашего прямоугольника) к сумме площадей всех прямоугольников в распределении. Чем больше прямоугольников вы используете, тем более точными будут полученные вероятности. Если бы вы использовали бесконечное число прямоугольников, то ваш расчет был бы точным.
Рассмотрим процедуру поиска площадей под кривой характеристического распределения на примере. Допустим, мы хотим найти вероятности, ассоциированные с каждым отрезком длиной 0,1 в интервале от -3 до +3 сигма. Отметьте, что в таблице (с. 183) рассмотрен интервал от -5 до +5 сигма. Дело в том, что лучше выйти на 2 сигмы за ограничительные параметры (-3 и +3 сигма в нашем случае), чтобы получить более точные результаты. Отметьте, что Х — это число стандартных единиц, на которое мы смещены от среднего значения. Далее идут значения четырех параметров. Следующий столбец — это столбец N'(X), который отражает высоту кривой в точке Х при этих значениях параметров. N'(X) рассчитывается из уравнения (4.06). Воспользуемся уравнением (4.06). Допустим, нам надо рассчитать N'(X) для Х= -3 со значениями параметров 0,02, 2,76, 0 и 1,78 для LOC, SCALE, SKEW и KURT соответственно. Сначала рассчитаем показатель асимметрии для уравнения (4.06). Формула для расчета С задается уравнением (4.07):
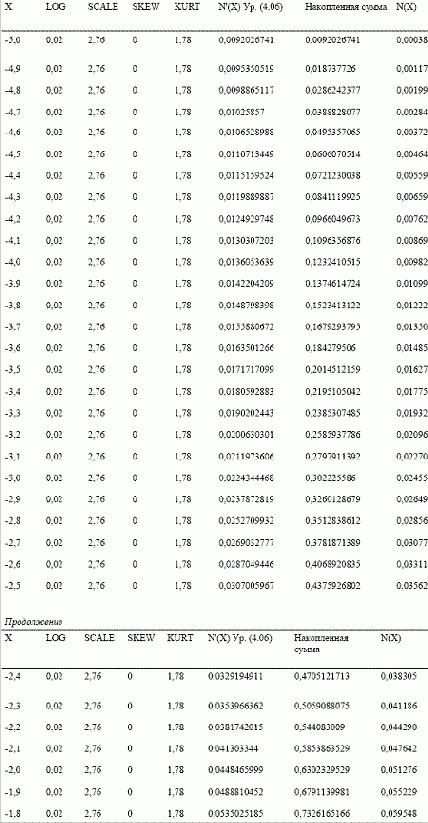
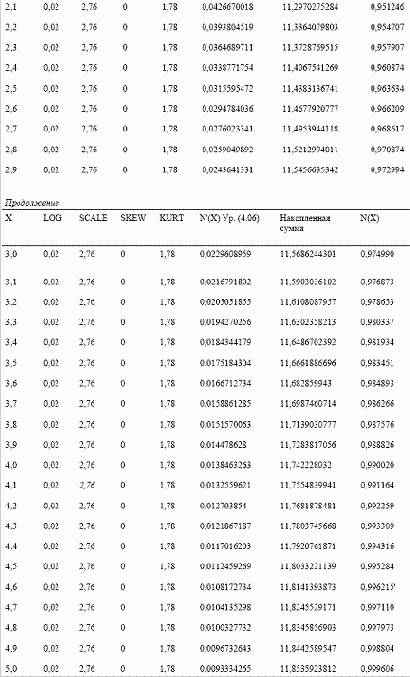


Таким образом, в точке Х = -3 N'(X) = 0,02243444681 (отметьте, что мы рассчитываем значения в столбце N'(X) для каждого значения X).
Рассчитаем очередной столбец, текущую сумму N'(X), накапливающуюся с ростом X. Это сделать достаточно просто. Далее рассчитаем столбец N(X) для вероятности, ассоциированной с каждым значением Х при данных значениях параметров. Формула для расчета N(X) выглядит следующим образом:
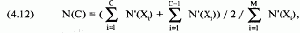
где С = текущее количество точек X;
М = общее количество точек X.
Уравнение (4.12) означает, что при каждом изменении Х необходимо добавить текущую сумму при данном значении Х к текущей сумме предыдущего значения X, затем разделить полученную сумму на 2. Далее полученный результат следует разделить на последнее значение в столбце текущей суммы N'(X) (накопленная сумма значений N'(X)). Это даст нам вероятность для значения Х при данных значениях параметров.
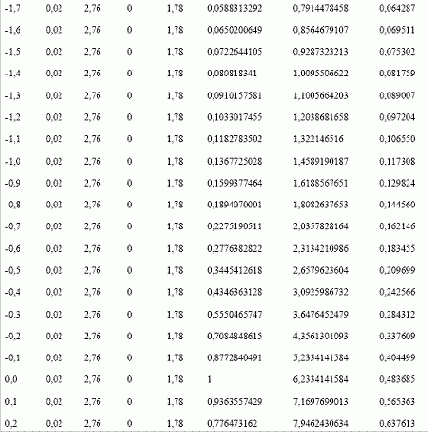
Таким образом, для Х = -3 текущая сумма N(X) = 0,302225586, а для предыдущего значения Х = -3,1 текущая сумма равна 0,2797911392. Сумма двух этих величин равна 0,5820167252. При делении на 2 мы получаем 0,2910083626. Разделив эту величину на последнее значение в столбце накопленной суммы N'(X), равное 11,8535923812, мы получаем 0,02455022522. Это и есть вероятность N(X) при стандартном значении Х = -3.
После того как мы вычислили накопленные вероятности для каждой сделки в фактическом распределении и вероятности для каждого приращения стандартного значения в нашем характеристическом распределении, мы можем осуществить тест К-С для значений параметров характеристического распределения, которые используются в настоящий момент. Однако сначала рассмотрим два важных момента.
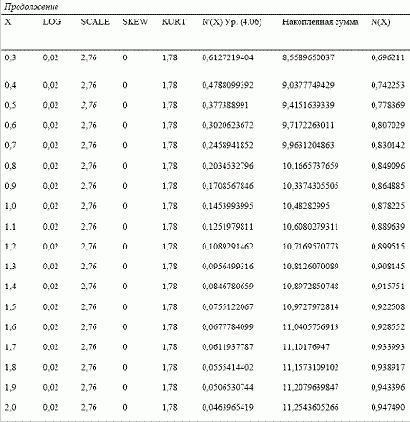
В примере с таблицей накопленных вероятностей, показанной ранее для нашего регулируемого распределения, мы рассчитывали вероятности с приращением стандартных значений 0,1. Это было сделано для наглядности. На практике вы можете получить большую степень точности, используя меньший шаг приращения. Приращение 0,01 в большинстве случаев является вполне приемлемым.
Скажем несколько слов о том, как для регулируемого распределения выбрать ограничительные параметры, то есть количество сигма с каждой стороны от среднего. В нашем примере мы использовали 3 сигма, но в действительности следует использовать абсолютное значение самой отдаленной точки от среднего.
Для нашего примера с 232 сделками крайнее левое (самое меньшее) стандартное значение составляет -2,96 стандартной единицы, а крайнее правое (самое большое) составляет 6,935321 стандартной единицы. Так как 6,93 больше, чем ABS(-2,96), мы должны взять 6,935321. Теперь добавим еще 2 сигма к этому значению для надежности и найдем вероятности для распределения от -8,94 до +8,94 сигма. Так как нам нужна хорошая точность, мы будем использовать приращение 0,01.
Рассчитаем вероятности для стандартных значений:
-8,94
-8,93
-8,92
-8,91
*
*
*
+8,94
Последнее, что мы должны сделать, прежде чем провести тест К-С, — это округлить фактические стандартные значения отобранных сделок с точностью 0,01 (так как мы используем 0,01 в качестве шага для теоретического распределения).
Например, значение 6,935321 не будет иметь соответствующей теоретической вероятности, ассоциированной с ним, так как оно находится между значениями 6,93 и 6,94. Так как 6,94 ближе к 6,935321, мы округляем 6,935321 до 6,94. Прежде чем начать процедуру оптимизирования наших параметров регулируемого распределения путем применения теста К-С, мы должны округлить фактические отсортированные нормированные сделки в соответствии с выбранным шагом.
Вместо округления стандартных значений сделок до ближайшего десятичного Х можно использовать линейную интерполяцию по таблице накопленных вероятностей, чтобы вычислить вероятности, соответствующие фактическим стандартным значениям сделок. Чтобы больше узнать о линейной интерполяции, посмотрите хорошую книгу по статистике, например «Управление деньгами на товарном рынке» Фреда Гема. Другие интересные книги указаны в списке рекомендованной литературы. До настоящего момента мы оптимизировали только параметры KURT и SCALE. Может показаться, что при нормировании данных параметр LOC должен быть приравнен к 0, а параметр SCALE — к 1. Это не совсем верно, так как реальное расположение распределения может не совпадать со средним арифметическим, а оптимальное значение ширины отличаться от единицы. Значения KURT и SCALE сильно связаны друг с другом. Таким образом, мы сначала попытаемся приблизительно определить оптимальные значения параметров KURT и SCALE. Для наших 232 сделок получаем SCALE =2,7, а KURT =1,9. Теперь попытаемся найти наиболее подходящие значения параметров.
Этот процесс займет достаточно много времени, даже если у вас хороший компьютер. Мы проведем цикл, изменяя параметр LOC от 0,1 до -0,1 по -0,05, параметр SCALE от 2,6 до 2,8 по 0,05, параметр SKEW от 0,1 до -0,1 по -0,05 и параметр KURT от 1,86 до 1,92 по 0,02. Результаты этого цикла дают оптимальное (самое низкое значение статистики К-С) при LOC = О, SCALE = 2,8, SKEW =0 и KURT =1,86. Затем мы осуществим третий цикл. На этот раз будем просматривать LOC от 0,04 до -0,04 по -0,02, SCALE от 2,76 до 2,82 по 0,02, SKEW от 0,04 до - 0,04 по -0,02 и KURT от 1,8 до 1,9 по 0,02. Результаты третьего цикла дают оптимальные значения LOC = 0,02, SCALE = 2,76, SKEW = 0 и KURT = 1,8. Мы нашли оптимальную окрестность, в которой параметры дают наилучшее приближение регулируемой характеристической функции к распределению реальных данных. Для последнего цикла мы будем просматривать LOC от 0 до 0,03 по 0,01, SCALE от 2,76 до 2,73 по -0,01, SKEW от 0,01 до -0,01 и KURT от 1,8 до 1,75 по -0,01. Результаты этого последнего прохода дают следующие оптимальные параметры для наших 232 сделок: LOC = 0,02, SCALE =2,76, SKEW = 0 и KURT =1,78.
Содержание раздела


