

7.4 Разделение наблюдений на группы
В SPSS можно выполнять анализ данных раздельно по группам. Группой в этом контексте называется определенное количество наблюдений с одинаковыми значениями признаков. Чтобы можно было производить обработку по группам, файл должен быть отсортирован по группирующим переменным. Такой переменной может быть, например, переменная sex. В этом случае все переменные со значением признака 1 (женский) образуют одну группу, а все переменные со значением признака 2 (мужской) — другую группу. С каждой группой можно проводить определенные операции, например, выполнять частотный анализ. При этом частотный анализ проводится раздельно для признаков мужской и женский. В SPSS такое разделение на группы можно выполнять автоматически. Рассмотрим следующий пример, основанный на опросе студентов об их психическом состоянии и социальном положении:
Проведем частотный анализ переменной psyche (психическое состояние) раздельно для всех изучаемых специальностей. В соответствии со значениями переменной fach (специальность) у нас образуются 9 групп (1 = Юриспруденция, 2 = Экономика, 3 = Гуманитарные науки, 4 = Психология и т.д.). В этом случае файл данных studium.sav должен быть сначала отсортирован по переменной fach. Поступите следующим образом:
-
Загрузите файл studium.sav в редактор данных.
-
Выберите в меню команды Data (Данные) Split File... (Разделить файл) Откроется диалоговое окно Split File.
Диалоговое окно Split File
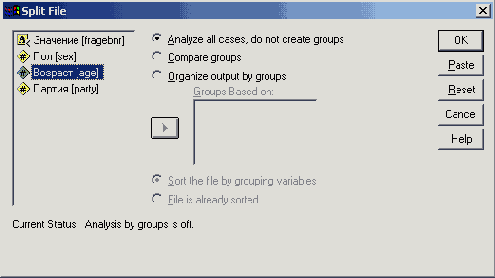
По умолчанию разделение на группы не предполагается. Если выбрать пункт Organize output by groups (Разделить вывод на группы), мы получим вывод результатов по каждой группе отдельно. Эти группы должны быть определены в поле Groups based on (Группы, созданные на основе) на базе соответствующих переменных.
Еще одну возможность предоставляет опция Compare Groups (Сравнить группы). Она организует вывод таким образом, что можно визуально сравнить разные группы друг с другом. Но сначала мы рассмотрим раздельный вывод.
-
Выберите опцию Organize output by groups. Для раздельного выполнения операций по группам необходимо, чтобы файл данных был предварительно отсортирован по этим группирующим переменным. По этой причине опция Sort the file by grouping variables (Сортировать файл по группирующим переменным) выбрана по умолчанию.
-
Перенесите переменную fach в поле Groups based on. Если выбирается несколько группирующих переменных, то последовательность, в которой они стоят в списке, определяет порядок или приоритет сортировки.
-
Щелкните на кнопке ОК. Файл studium.sav будет отсортирован по переменной fach, то есть разбит на группы в соответствии с ее значениями. Сообщение File split on (Разделение файла включено) в строке состояния внизу окна SPSS информирует об активации режиме разделения.
-
Выполните частотный анализ переменной psyche.
Вы получите следующий результат (ниже для экономии места показаны частотные таблицы только для специальностей Юриспруденция и Естественные науки).
Специальность = Юриспруденция
Статистика(а)
|
Психическое состояние | |
|
N Valid Missing |
22 0 |
|
а. Специальность = Юриспруденция | |
Психическое состояние(а)
|
Frequency |
Percent |
Valid Percent |
Cumulative Percent | ||
|
Valid |
Крайне неустойчивое |
2 |
9,1 |
9,1 |
9,1 |
|
Неустойчивое |
5 |
22,7 |
22,7 |
31,8 | |
|
Устойчивое |
12 |
54,5 |
54,5 |
86,4 | |
|
Очень устойчивое |
3 |
13,6 |
13,6 |
100,0 | |
| Total | 22 | 100,0 | 100,0 | ||
|
Спциальность = юриспруденция | |||||
Специальность = Естественные науки
Статистика(а)
|
|
N Valid Missing |
18 1 |
|
а. Специальность = Естественные науки | ||
Психическое состояние(а)
|
Frequency |
Percent |
Valid Percent |
Cumulative Percent | ||
|
Valid |
Крайне неустойчивое |
1 |
5,3 |
5,6 |
5,6 |
|
Неустойчивое |
4 |
21,1 |
22,2 |
27,8 | |
|
Устойчивое |
11 |
57,9 |
61,1 |
88.9 | |
|
Очень устойчивое |
2 |
10,5 |
11,1 |
100,0 | |
|
Всего |
18 |
94,7 |
100,0 |
| |
|
Missing |
нет данных |
1 |
5,3 |
|
|
|
|
Всего |
|
19 |
100,0 |
|
а. Специальность = Естественные науки
Как видно, результаты частотного анализа переменной psyche выводятся раздельно по специальностям студентов.
-
Теперь выберите другой пункт — Compare groups (Сравнить группы).
-
Снова выполните частотный анализ переменной psyche. Вы получите следующую результирующую таблицу:
Психическое состояние
|
Специальность |
|
|
Frequency |
Percent |
Valid Percent |
Cumulative Percent |
|
Юриспру- денция |
Valid |
Крайне неустойчивое |
2 |
9,1 |
9,1 |
9,1 |
|
|
Неустойчивое |
5 |
22,7 |
22,7 |
31,8 | |
|
|
Устойчивое |
12 |
54,5 |
54,5 |
86,4 | |
|
|
Очень устойчивое |
3 |
13,6 |
13,6 |
100,0 | |
|
|
Всего |
22 |
100,0 |
100,0 |
| |
|
Экономика |
Valid |
Крайне неустойчивое |
1 |
5,3 |
5,6 |
5,6 |
|
|
Неустойчивое |
4 |
21,1 |
22,2 |
27,8 | |
|
|
Устойчивое |
11 |
57,9 |
61,1 |
88,9 | |
|
|
Очень устойчивое |
2 |
10,5 |
11,1 |
100,0 | |
|
|
Всего |
18 |
94,7 |
100,0 |
| |
|
Missing |
нет данных |
1 |
5,3 |
|
| |
|
Total |
19 |
100,0 |
|
|
| |
|
Гуманитар- ные науки |
Valid |
Крайне неустойчивое |
10 |
40,0 |
40,0 |
40,0 |
|
|
Неустойчивое |
14 |
56,0 |
56,0 |
96,0 | |
|
|
Устойчивое |
1 |
4,0 |
4,0 |
100,0 | |
|
|
Всего |
25 |
100,0 |
100,0 |
| |
|
Психология |
Valid |
Крайне неустойчивое |
3 |
27,3 |
27,3 |
27,3 |
|
|
Неустойчивое |
6 |
54,5 |
54,5 |
81,8 | |
|
|
Устойчивое |
2 |
18,2 |
18,2 |
100,0 | |
|
|
Всего |
11 |
100,0 |
100,0 |
| |
|
Теология |
Valid |
Крайне неустойчивое |
2 |
22,2 |
22,2 |
22,2 |
|
|
Неустойчивое |
5 |
55,6 |
55,6 |
77,8 | |
|
|
Устойчивое |
2 |
22,2 |
22,2 |
100,0 | |
|
|
Всего |
9 |
100,0 |
100,0 |
| |
|
Медицина |
Valid |
Крайне неустойчивое |
1 |
10,0 |
10,0 |
10,0 |
|
|
Неустойчивое |
3 |
30,0 |
30,0 |
40,0 | |
|
|
Устойчивое |
5 |
50,0 |
50,0 |
90,0 | |
|
|
Очень устойчивое |
1 |
10,0 |
10,0 |
100,0 | |
|
|
Всего |
10 |
100,0 |
100,0 |
| |
|
Естествен- ные науки |
Valid |
Неустойчивое |
3 |
33,3 |
33,3 |
33,3 |
|
|
Устойчивое |
6 |
66,7 |
66,7 |
100,0 | |
|
|
Всего |
9 |
100,0 |
100,0 |
| |
|
Техника |
Valid |
Крайне неустойчивое |
1 |
50,0 |
50,0 |
50,0 |
|
|
Устойчивое |
1 |
50,0 |
50,0 |
100,0 | |
|
|
Всего |
2 |
100,0 |
100,0 |
| |
|
Прочие |
Valid |
Устойчивое |
1 |
100,0 |
100,0 |
100,0 |
Учтите, что файл данных останется разделенным на подгруппы, пока вы не деактивируете соответствующие опции. Для этого поступите следующим образом:
-
Выберите в меню команды Data (Данные) Split File... (Разделить файл)
-
В диалоговом окне Split File выберите опцию Analyze all cases, do not create groups (Анализировать все наблюдения, не создавать группы). Теперь разделение файла убрано.
-
Если требуется дополнительно убрать сортировку по специальностям, выберите в меню следующие команды Data (Данные) Sort Cases... (Сортировать наблюдения)
-
Перенесите переменную fragebnr (код анкеты) в список переменных сортировки и подтвердите операцию кнопкой ОК. Данные будут отсортированы в исходном порядке — по номерам анкет.
На этом мы заканчиваем обзор возможностей отбора данных в SPSS и переходим к изучению средств модификации данных.