

Find Dependencies (FD) - N-мерный анализ распределений
Данный алгоритм обнаруживает в исходной таблице группы записей, для которых характерно наличие функциональной связи между целевой переменной и независимыми переменными, оценивает степень (силу) этой зависимости в терминах стандартной ошибки, определяет набор наиболее влияющих факторов, отсеивает отскочившие точки. Целевая переменная для FD должна быть числового типа, в то время как независимые переменные могут быть и числовыми, и категориями, и логическими.
Алгоритм работает очень быстро и способен обрабатывать большие объемы данных. Его можно использовать как препроцессор для алгоритмов FL, PN, LR, так как он уменьшает пространство поиска, а также как фильтр отскочивших точек или, в обратной постановке, как детектор исключений. FD создает правило табличного вида, однако, как и все правила PolyAnalyst, оно может быть вычислено для любой записи таблицы.
Find Clusters (FC) - N-мерный кластеризатор
Этот метод применяется тогда, когда надо выделить в некотором множестве данных компактные типичные подгруппы (кластеры), состоящие из близких по своим характеристикам записей. Алгоритм FC сам определяет набор переменных, для которых разбиение наиболее значимо. Результатом работы алгоритма является описание областей (диапазонов значений переменных), характеризующих каждый обнаруженный кластер, и разбиение исследуемой таблицы на подмножества, соответствующие кластерам. Если данные являются достаточно однородными по всем своим переменным и не содержат "сгущений" точек в каких-то областях, этот метод не даст результатов. Надо отметить, что минимальное число обнаруживаемых кластеров равно двум - сгущение точек только в одном месте в данном алгоритме не рассматривается как кластер. Кроме того, этот метод в большей степени, чем остальные, предъявляет требования к наличию достаточного количества записей в исследуемой таблице, а именно: минимальное количество записей в таблице, в которой может быть обнаружено N кластеров, равно (2N-1)4.
Алгоритм Enhanced k-means Clustering
В этом алгоритме число кластеров изначально задается пользователем. Кластеризация проводится только по числовым атрибутам, их число не должно быть слишком велико. Количество записей может быть каким угодно.
Алгоритм O-Cluster
Этот алгоритм, в отличие от предыдущего, автоматически определяет число кластеров. Он может работать как с числовыми, так и с категориальными атрибутами. Может работать с большим числом атрибутов, т.е. более 10, и с большим количеством записей, более 1000.
Состав и назначение аналитической платформы Deductor (разработчик - компания BaseGroup Labs [115]). Deductor состоит из двух компонентов: аналитического приложения Deductor Studio и многомерного хранилища данных Deductor Warehouse [48] .
Архитектура системы Deductor представлена на рис. 26.1.
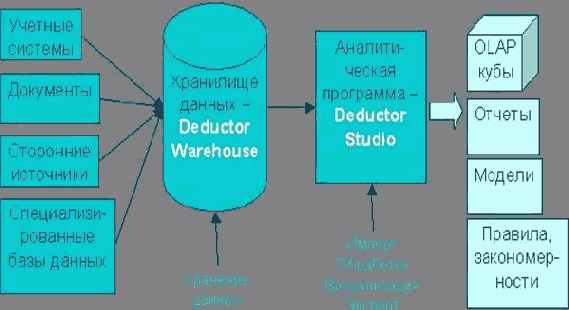
Deductor Warehouse - многомерное хранилище данных, аккумулирующее всю необходимую для анализа предметной области информацию. Использование единого хранилища позволяет обеспечить непротиворечивость данных, их централизованное хранение и автоматически создает всю необходимую поддержку процесса анализа данных. Deductor Warehouse оптимизирован для решения именно аналитических задач, что положительно сказывается на скорости доступа к данным.
Deductor Studio - это программа, предназначенная для анализа информации из различных источников данных. Она реализует функции импорта, обработки, визуализации и экспорта данных. Deductor Studio может функционировать и без хранилища данных, получая информацию из любых других источников, но наиболее оптимальным является их совместное использование.