

Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), так и переменных (столбцов) [54]. Можно считать, что в последнем случае роль объектов играют переменные, а роль переменных - столбцы.
В этом методе реализуется иерархический агломеративный алгоритм, смысл которого заключается в следующем. Перед началом кластеризации все объекты считаются отдельными кластерами, в ходе алгоритма они объединяются. Вначале выбирается пара ближайших кластеров, которые объединяются в один кластер. В результате количество кластеров становится равным N-1. Процедура повторяется, пока все классы не объединятся. На любом этапе объединение можно прервать, получив нужное число кластеров. Таким образом, результат работы алгоритма агрегирования зависит от
способов вычисления расстояния между объектами и определения близости между кластерами.
Для определения расстояния между парой кластеров могут быть сформулированы различные подходы. С учетом этого в SPSS предусмотрены следующие методы:
• Среднее расстояние между кластерами (Between-groups linkage), устанавливается по умолчанию.
• Среднее расстояние между всеми объектами пары кластеров с учетом расстояний внутри кластеров (Within-groups linkage).
• Расстояние между ближайшими соседями -ближайшими объектами кластеров (Nearest neighbor).
• Расстояние между самыми далекими соседями (Furthest neighbor).
• Расстояние между центрами кластеров (Centroid clustering) или центроидный метод. Недостатком этого метода является то, что центр объединенного кластера вычисляется как среднее центров объединяемых кластеров, без учета их объема.
• Метод медиан -тот же центроидный метод, но центр объединенного кластера вычисляется как среднее всех объектов (Median clustering).
• Метод Варда.
Порядок агломерации (протокол объединения кластеров) представленных ранее данных приведен в таблице 13.2. В протоколе указаны такие позиции:
• Stage -стадии объединения (шаг);
• Cluster Combined -объединяемые кластеры (после объединения кластер принимает минимальный номер из номеров объединяемых кластеров);
• Coefficients -коэффициенты.
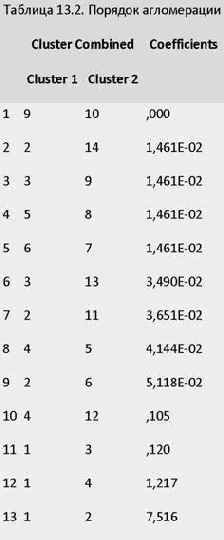
Так, в колонке Cluster Combined можно увидеть порядок объединения в кластеры: на первом шаге были объединены наблюдения 9 и 10, они образовывают кластер под номером 9, кластер 10 в обзорной таблице больше не появляется. На следующем шаге происходит объединение кластеров 2 и 14, далее 3 и 9, и т.д.
В колонке Coefficients приведено количество кластеров, которое следовало бы считать оптимальным; под значением этого показателя подразумевается расстояние между двумя кластерами, определенное на основании выбранной меры расстояния.
В нашем случае это квадрат евклидова расстояния, определенный с использованием стандартизированных
• Z-шкалы (Z-Scores). Из значений переменных вычитается их среднее, и эти значения делятся на стандартное отклонение.
• Разброс от -1 до 1. Линейным преобразованием переменных добиваются разброса значений от -1 до 1. • Разброс от 0 до 1. Линейным преобразованием переменных добиваются разброса значений от 0 до 1. • Максимум 1. Значения переменных делятся на их максимум.
• Среднее 1. Значения переменных делятся на их среднее.
• Стандартное отклонение 1. Значения переменных делятся на стандартное отклонение.
Кроме того, возможны преобразования самих расстояний, в частности, можно расстояния заменить их абсолютными значениями, это актуально для коэффициентов корреляции. Можно также все расстояния преобразовать так, чтобы они изменялись от 0 до 1.