

Мы уже построили нейросеть для важной задачи принятия решений и вручили ее заказчику — дяде Рамзаю.
Теперь еще раз тщательно проследим за применением принципа динамического совмещения обучения системы управления с получением решений и установим в схеме на рис. 6.2 целесообразность, место и способ использования нейронной сети как основного реального средства искусственного интеллекта. Прежде всего заметим, что основным естественным и целесообразным местом применения нейросети здесь является база знаний, ранее реализованная с помощью ассоциативной памяти (см. рис. 6.1). Надо только позаботиться о том, чтобы там находились не численные значения информации, а ее вес или достоверность, т. е. не сама информация должна обрабатываться нейросетью, а ее логический эквивалент. Ведь принцип искусственного интеллекта направлен на параллельную обработку логических высказываний, а вовсе не на числовую обработку информации, как это делается при решении «нейроподобных» задач с использованием нейросети в роли спецпроцессора.
Пусть нейросеть в качестве базы знаний имеет вид, представленный на рис. 6.3.
Нейронырецепторы закреплены за значениями элементов входного вектора. Значит, в режиме обучения установилось соответствие между величиной возбуждения рго нейрона входного слоя и достоверностью того, что 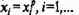
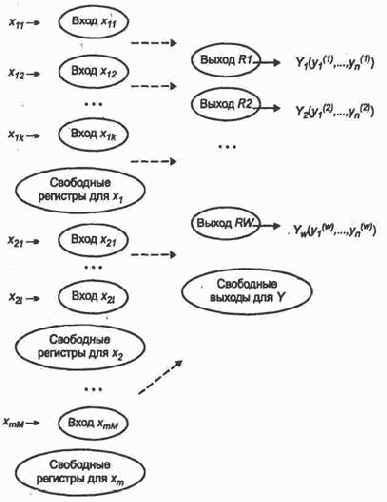
Как указано выше, при обучении положим эту достоверность равной единице, а в процессе распознавания она может быть какой угодно, даже не удовлетворяющей свойству полноты событий.
После обучения с помощью различных эталонов методом трассировки можно добиться соответствия вида {Входы 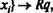
![]()
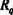
Для нахождения этих значений в зависимости от исходных данных применяется моделирование наряду с экспериментом или с экспертными оценками. Таким образом, модель, эксперимент или эксперт играют роль учителя.
Первоначально обученная таким образом нейросеть используется в рабочем режиме распознавания и в режиме совместной работы с моделью. Конечно, справедливо считать, что нейросеть обучена недостаточно, и подобно «пристрелке реперов» любой удобный случай используется для того, чтобы с помощью модели испытать и в случае необходимости дополнить знания нейросети.
Для этого модель случайно или целенаправленно — по обоснованному плану, генерирует некоторую ситуацию, характеризующуюся значением компонент входного вектора X. По каждой компоненте определяется вес или достоверность того, что ее значение совпадает с подмножеством значений представленных входным слоем нейросети или с диапазонами значений.
Например, известна реакция сети на значения х = 2, х = 5, х = 6, а модель сгенерировала значение х = 5,7.
Это может означать необходимость (реализуется некоторая процедура) формирования значений возбуждения

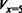
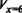
Здесь индексы указывают нейроны входного слоя, соответствующие данному значению параметра. Такая процедура выполняется по всем компонентам, отображенным входным слоем.
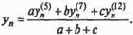
Подставляем данное решение в модель и устанавливаем, удовлетворяет ли нас точность. Если удовлетворяет, делаем положительный вывод об обученности нейросети и продолжаем испытание по другим исходным данным. Если нет, сеть необходимо «доучить», продемонстрировав высокий уровень обратной связи.
Для этого придется ввести в действие новые рецепторы в соответствии с теми значениями исходных данных или их диапазонами, которые ранее не были представлены. Например, придется ввести рецептора соответствии со значением х = 5,7.
Далее, выделим нейрон выходного слоя в соответствии с правильным решением, полученным в результате моделирования. Затем выполним трассировку для того, чтобы появление нового эталона с единичной достоверностью исходных данных приводило к максимальному возбуждению выделенного нейрона выходного слоя, ответственного за получение правильного решения.
Таким образом, сеть может обучаться до тех, пор, пока не прекратятся сбои, что маловероятно. Следовательно, в таком режиме она должна работать в течение всего жизненного цикла, реализуя известную пословицу «Век живи — век учись».
Здесь наглядно представлена замечательная возможность нейросети: табличная аппроксимация функции многих переменных, дополненная процедурой интерполяции (экстраполяции) для нахождения произвольного значения вектора аргумента и приближенного значения векторной функции. При этом входной вектор возбуждений рецепторов преобразуется в максимальное или усредненное значение, возбуждения нейронов выходного слоя, указывающее на соответствующее значение вектора функции. Практически столь простым способом мы построили аппроксимацию векторной функции от векторного аргумента!
Такая аппроксимация выполняется и в более явном виде, ибо каждая 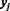
Следовательно, сеть строится и обучается так, чтобы заданное значение X = 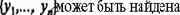
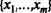
![]() к максимальному (или усредненному) значению возбуждения другого нейрона выходного слоя, указывающего на значение
к максимальному (или усредненному) значению возбуждения другого нейрона выходного слоя, указывающего на значение 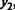
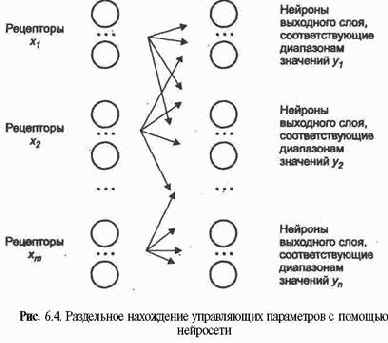
В результате выходной слой разбивается на области, каждая из которых закреплена за своим 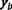
![]()
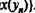
Следует обратить внимание не только на высокую производительность такого рода самообучающихся систем в рабочем режиме, но и на их адаптивность, развитие, живучесть и т.д.