
| 
|
|
|
|
совокупность ее лингвистических значений, U - носитель, G - синтаксическое правило, порождающее термы множества Т, М - семантическое правило, которое каждому лингвистическому значению со ставит в соответствие его смысл М(со), причем М(со) обозначает нечеткое подмножество носителя U.
Таким образом, конструктивное описание лингвистической переменной завершено.
Для классических множеств вводятся операции:
- пересечение множеств - операция над множествами А и В, результатом которой является множество С = А п В, которое содержит только те элементы, которые принадлежат и множеству А и множеству В;
- объединение множеств - операция над множествами А и В, результатом которой является множество С = А и В, которое содержит те элементы, которые принадлежат множеству А или множеству В или обоим множествам;
- отрицание множеств - операция над множеством А, результатом которой является множество С = і А, которое содержит все элементы, которые принадлежат универсальному множеству, но не принадлежат множеству А.
Заде предложил набор аналогичных операций над нечеткими множествами через операции с функциями принадлежности этих множеств. Так, если множество А задано функцией цд(и), а множество В задано функцией Цв(и), то результатом операций является множество С с функцией принадлежности рс(и), причем:
Нечеткое число - это нечеткое подмножество универсального множества действительных чисел, имеющее нормальную и выпуклую функцию принадлежности, то есть такую, что а) существует такое значение носителя, в котором функция принадлежности равна единице, а также а) при отступлении от своего максимума влево или вправо функция принадлежности убывает.
Рассмотрим два типа нечетких чисел, которые нам понадообятся для дальнейшего.
4.8.1. Трапециевидные (трапезоидные) нечеткие числа
Исследуем некоторую квазистатистику и зададим лингвистическую переменную Q = Значение параметра U, где U - множество значений носителя квазистатистики. Выделим два терм-множества значений: Ті = U у лежит в диапазоне примерно от а до Ь с нечетким подмножеством Мі и безымянное значение Т2 с нечетким подмножеством М2, причем выполняется М2 = i Mi.
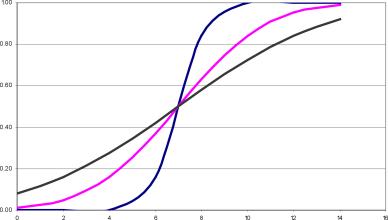
Тогда функция принадлежности р.ті(и) имеет трапезоидный вид, как показано на рис. 4.

Теперь для той же лингвистической переменной зададим терм-множество Ti={U приблизительно равно а}. Ясно, что а ± 8 а, причем по мере убывания 8 до нуля степень уверенности в оценке растет до единицы. Это, с точки зрения функции принадлежности, придает последней треугольный вид (рис.
2.4), причем степень приближения характеризуется экспертом.

Целый раздел теории нечетких множеств - мягкие вычисления (нечеткая арифметика) - вводит набор операций над нечеткими числами. Эти операции вводятся через операции над функциями принадлежности на основе так называемого сегментного принципа.
Определим уровень принадлежности а как ординату функции принадлежности нечеткого числа. Тогда пересечение функции принадлежности с нечетким числом дает пару значений, которые принято называть границами интервала достоверности.
Зададимся фиксированным уровнем принадлежности а и определим соответствующие ему интервалы достоверности по двум нечетким числам А и В: [ац аг] и [Ьц Ьа], соответственно. Тогда основные операции с нечеткими числами сводятся к операциям с их интервалами достоверности. А операции с интервалами, в свою очередь, выражаются через операции с действительными числами -границами интервалов:
- операция сложения:
[аі, a2] (+) [bi, b2] - [ai + bi, a2 + b2],
(6)
- операция вычитания:
[аь а2] (-) [Ьь Ь2] = [аі - b2, а2 - Ьі],
(7)
- операция умножения:
[аі, а2] (х) [bi, b2] = [аі х Ьь а2 х Ь2],
(8)
- операция деления:
[аі, а2] (/) [bi, b2] = [аі / b2, а2 / Ьі],
(9)
- операция возведения в степень:
[аь а2] (Л) і = [а/ , а2‘].
(10)
Из существа операций с трапезоидными числами можно сделать ряд важных утверждений (без доказательства):
- действительное число есть частный случай треугольного нечеткого числа;
- сумма треугольных чисел есть треугольное число;
- треугольное (трапезоидное) число, умноженное на действительное число, есть треугольное (трапезоидное) число;
- сумма трапезоидных чисел есть трапезоидное число;
- сумма треугольного и трапезоидного чисел есть трапезоидное число.
Анализируя свойства нелинейных операций с нечеткими числами (например, деления), исследователи приходят к выводу, что форма функций принадлежности результирующих нечетких чисел часто близка к треугольной. Это прозволяет аппроксимировать результат, приводя его к треугольному виду.
И, если приводимость налицо, тогда операции с треугольными числами сводятся к операциям с абсциссами вершин их функций принадлежности.
То есть, если мы вводим описание треугольного числа набором абсцисс вершин (а, Ь, с), то можно записать:
(аі, bi, ci) + (а2, b2, с2) s (аі + a2, bi + b2, d + c2)
(11)
Это - самое распространенное правило мягких вычислений.
Нечеткая последовательность - это пронумерованное счетное множество нечетких чисел.
Нечеткая прямоугольная матрица - это дважды индексированное конечное множество нечетких чисел, причем первый индекс пробегает М строк, а второй - N столбцов. При этом, как и в случае матриц действительных чисел, операции над нечеткими прямоугольными матрицами сводятся к операциям над нечеткими компонентами этих матриц. Например,
где все операции над нечеткими числами производятся так, как они введены параграфом выше.
Поле нечетких чисел - это несчетное множество нечетких чисел.
Нечеткая функция - это взаимно однозначное соответствие двух полей нечетких чисел. В наших приложениях область определения нечеткой функции явзяется осью действительных чисел, то есть вырожденным случаем поля нечетких чисел, когда их треугольные функции принадлежности вырождаются в точку с координатами (а, 1).
Нечеткую функцию уместно назвать по типу тех чисел, которые характеризуют область ее значений. Если поле значений - это поле треугольных чисел, то и саму функцию уместно назвать треугольной.
Например [18], прогноз продаж компании (нарастающим итогом) задан тремя функциями вещественной переменной: fi(T) - оптимистичный прогноз, ?г(Т) -пессимистичный прогноз, f3(T) - среднеожидаемые значения продаж, где Т - время прогноза. Тогда лингвистическая переменная Прогноз продаж в момент Т есть треугольное число ( fi(T), f2(T), f3(T) ), а все прогнозное поле есть треугольная нечеткая функция (рис.
2.5), имеющая вид криволинейной полосы.

Тогда всем правдоподобным вероятностным гипотезам отвечает множество векторов К , которое в N-мерном фазовом пространстве представляет собой выпуклую область с нелинейными границами.
Впишем в эту область N-мерный параллелепипед максимального объема, грани которого сориентированы параллельно фазовым осям. Тогда этот параллелепипед представляет собой усечение К и может быть описан набором интервальных диапазонов по каждой компоненте
К = (хп, х!2; х21, x22;...xNi, xN2) е К . (15)
Назовем К зоной предельного правдоподобия. Разумеется, контрольная точка попадает в эту зону , то есть выполняется
ХцХіь Хі2,..., xNixNL xN2, (16)
что вытекает из унимодальности и гладкости критерия правдоподобия.
Тогда мы можем рассматривать числа (хц, x;l, хі2) как треугольные нечеткие параметры плотности распределения, которая и сама в этом случае имеет вид нечеткой функции. А зона предельного правдоподобия тогда есть не что иное, как нечеткий вектор.
Мы видим, что полученное вероятностное распределение имеет не только частотный, но и субъективный смысл, так как зона предельного правдоподобия зависит от того, как мы бракуем вероятностные гипотезы. Представляется, что такое описание всецело отвечает природе квазистатистики, как мы ее здесь вводим.
Чем хуже условия для выдвижения правдоподобных вероятностных гипотез, чем тяжелее обосновывать такое правдоподобие, - тем большее значение занимает фактор экспертной оценки. То вероятностное описание, что мы имеем в итоге, - это гибрид, который обещает быть плодотворным.
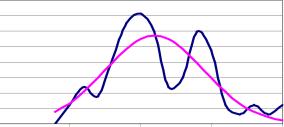
В качестве примера можно рассмотреть нормальный закон распределения с нечетким среднеквадратическим отклонением (рис. 7).
Эта нечеткая функция не имеет полосового вида. И тут замое время заметить, что функция с треугольными нечеткими параметрами в общем случае сама не является треугольной и к треугольному виду не приводится.
Зато выполняется нормировочное условие:
Г p(u,tf)du= 1, (17)
J-cc
где правая часть представляет собой нечеткое число с вырожденной в точку функцией принадлежности. Интеграл же, не определенный для не четких функций общего вида, представляет здесь предел сумм
? „ Нт х. „ (( Аи
р(и, К )du = У (р(и, К ) + р(п + Аи, К )) (18)
Аи - Оу, 2
Приложим все сказанное к нечеткой оценке параметров доходности и риска фондового индекса. Пусть у нас есть квазистатистика доходностей (гц ... і\) мощности N и соответствующая ей гистограмма (?і,...,?м) мощности М. Для этой квазистатистики мы подбираем двупараметрическое нормальное распределение ср() с матожиданием ц и дисперсией а, руководствуясь критерием правдоподобия
| Таблица 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
| Таблица 2 | |||||||||||||||||||||||||||||||||||||
|
Назовем формальным знанием высказывание естественного языка, обладающее следующей структурой:
ЕСЛИ (А2Ч?. An-i'Fn-iAn), ТО В, (24)
где {А,}, В - атомарные высказывания (предикаты), 'F, - логические связки вида И/ИЛИ, N - размерность условия, причем атомарные высказывания - это
а?Х, (25)
где а - определяемый объект {аргумент), ? - логическая связка принадлежности вида ЕСТЬ/НЕ ЕСТЬ, X - обобщение (класс объектов). Также соблюдается правило очередности в рассмотрении фразы для понимания: сначала все связки И применяются к двум смежным предикатам, а затем все связки ИЛИ применяются к результатам предшествующих операций.
Например, классический вывод Если Сократ человек, а человек смертен, то и Сократ смертен можно преобразовать к структуре формального знания по следующим правилам:
- вводится два класса объектов Хі = Человек (Люди) и Х2 = Смертный (-ая, -ое;
- рассматриваются два аргумента: аі = Сократ, а2 = Человек = Хі.
Тогда наше знание имеет формулу
ЕСЛИ аі ЕСТЬ Хі И (а2 = Хі) ЕСТЬ Х2
ТО аі ЕСТЬ Х2 (26)
Очень часто в структуре знаний классы объектов являются нечеткими понятиями. Также высказывающиеся лица могут делать выводы, содержащие элементы неуверенности, оценочности.
Это заставляет нас переходить от знаний в классическом понимании к знаниям нечетким.
Введем следующий набор лингвистических переменных со своим терм-множеством значений:
? = Отношение принадлежности = (Принадлежит, Скорее всего принадлежит, Вероятно принадлежит,...., Вероятно не принадлежит, Скорее всего не принадлежит, Не принадлежит}
(27)
А = Отношение следования = (Следует, Скорее всего следует, Вероятно следует,...., Вероятно не следует, Скорее всего не следует, Не следует }
(28)
AND/OR = Отношение связи = (И/ИЛИ, Скорее всего И/ИЛИ, Вероятно
И/ИЛИ,....}
(29)
Вводя эти переменные, мы предполагаем, что они содержат произвольное число оттеночных значений, ранжированных по силе (слабости) в определенном порядке. Носителем этих переменных может выступать единичный интервал.
Тогда под нечетким знанием можно понимать следующий формализм:
(30)
ЕСЛИ (аііХі 'Еі а2?2Х2 'Р2... а\-?\-Х\) Д а\- і?\ іX\ 1,
где аь X; -значения своих лингвистических переменных, 0! -значение переменной принадлежности из ?, Ті -значение переменной связи из AND/OR, Д - терм-значение переменной следования из А.
Характерным примером нечеткого знания является высказывание типа: Если ожидаемое в ближайшей перспективе отношение цены акции к доходам по ней порядка 10, и (хотя и ие обязательно) капитализация этой компании на уровне 10 млрд, долларов, то, скорее всего, эти акции следует покупать. Курсивом обозначены все оценки, которые делают это знание нечетким.
Поскольку нечеткое знание определяется через лингвистические переменные, то и операции нечеткого логического вывода можно количественно определить на базе операций с соответствующими функциями принадлежности. Однако детальное рассмотрение этого вопроса мы опускаем.
С некоторых пор нечеткие знания начали активно применяться для выработки брокерских рекомендаций по приобретению (удержанию, продаже) ценных бумаг. Например, монография [20] рассматривает вопрос о целесообразности инвестирования в фондовые активы в зависимости от характера экономического окружения, причем параметры этого окружения являются нечеткими значениями.
На сайте [21] автор вышеупомянутой монографии поддерживает бюллетень макроэкономических индикаторов и соответствующих условий инвестирования на тех или иных рынках.
На нечетких знаниях могут быть организованы специализированные экспертные системы, реализующие механизм нечетко-логического вывода. Простейший пример такого рода системы мы находим на сайте [22], где выработка опционной стратегии сопровождается нечеткой предварительной оценкой характера рынка.
В этом смысле также представляет интерес работа [23].
Теория нечетких множеств открывает новые возможности для интерпретации наблюдений, полученных опытным путем, потому что дает исследователю основания для анализа неоднородных и недостаточных выборок, которые классическая теория вероятности законно игнорирует.
Появляется простор для великого компромисса, когда исходная дурная неопределенность начинает работать на правах неопределенности канонической, но в модели попадают нечеткости, которые выражают степень субъективной уверенности эксперта в своей правоте. Тем самым неопределенность проходит структуризацию, получая формально описанную границу, отделяющую нашу уверенность от неуверенности, знание от незнания.
Законы, выраженные в нечеткой или нечетко-вероятностной форме, являют собой синтез объективных и субъективных моделей. Таким образом, активность эксперта не игнорируется, а приобретает модельные формы
Также надо отметить, что огромное количество вероятностных приложений в экономике опирается на наивные представления практиков о том, что их вероятностные гипотезы не требуют подтверждения правдоподобия. Если бы вопрос о подтверждении гипотез встал ребром и встал так, как это понимают классики математической статистики, то можно уверенно утверждать, что львиная доля вероятностных гипотез в экономике была бы забракована.
Категория квазистатистики позволяет получить оценку правдоподобия в новом качестве, в новом смысле, с оттенком субъективного доверия эксперта к полученным им гипотезам.
Модифицированный метод Марковица
Исторически первым методом оптимизации фондового портфеля был метод, предложенный в Марковицем в [24]. Суть его в следующем.
Пусть портфель содержит N типов ценных бумаг (ЦБ), каждая из которых характеризуется пятью параметрами:
начальной ценой W)o одной бумаги перед помещением ее в портфель; числом бумаг пі в портфеле;
начальными инвестициями Sio в данный портфельный сегмент, причем Sio = Wio х щ; (31)
среднеожидаемой доходностью бумаги г,; ее стандартным отклонением сц от значения г,.
Из перечисленных условий ясно, что случайная величина доходности бумаги имеет нормальное распределение с первым начальным моментом г, и вторым центральным моментом оі. Это распределение не обязательно должно быть нормальным, но из условий винеровского случайного процесса нормальность вытекает автоматически.
Сам портфель характеризуется:
суммарным объемом портфельных инвестиций S; - долевым ценовым распределением бумаг в портфеле (xj, причем для исходного портфеля выполняется
Zx =1
(32)
‘-то
s
i = 1.....N;
х, =
1=1
корреляционной матрицей {pi,}, коэффициенты которой характеризуют связь между доходностями і-ой и j-ой бумаг. Если рі, = -1, то это означает полную отрицательную корреляцию, если р,, = 1 - имеет место полно положительная корреляция.
Всегда выполняется рп = 1, так как ценная бумага полно положительно коррелирует сама с собой.
Таким образом, портфель описан системой статистически связанных случайных величин с нормальными законами распределения. Тогда, согласно теории случайных величин, ожидаемая доходность портфеля г находится по формуле
N
г=Ехіхг’ (33)
і=і
а стандартное отклонение портфеля ст -
= (ЕЕХ. ххі хРц XG XGj2- (34)
i=i j=i
Задача управления таким портфелем имеет следующее описание: определить вектор {хі}, максимизирующий целевую функцию г вида (33) при заданном ограничении на уровень риска ст, оцениваемый (34):
Iхopt} = {х} I г - max,c=const стм, (35)
где стм - риск бумаги с максимальной сред неожидаемой доходностью. Запись (35) есть не что иное, как классическая задача квадратичной оптимизации, которая может решаться любыми известными вычислительными методами.
Замечание. В подходе Марковица к портфельному выбору под риском понимается не риск неэффективности инвестиций, а степень колеблемости ожидаемого дохода по портфелю, причем как в меньшую, так и в большую сторону.