
| 
|
|
|
|
Когда потенциал действия достигает окончания аксона, молекулы медиатора выходят из внутриклеточных маленьких пузырьков, где они хранятся, в синаптическую щель пространство шириной 20 нм между мембранами пресинаптической и постсинаптической клеток. Когда возбуждение достигает пика, начинается координированное выделение молекул нейромедиатора.
Если же мембрана стабилизируется на уровне потенциала покоя, эффект будет тормозным.
Каждый синапс дает лишь незначительный эффект на активность аксона нейрона. Чтобы установилась интенсивность выхода, каждый нейрон должен непрерывно интегрировать до 1000 синаптических входов.
Еще в начале века нейрофизиологам стала ясна исключительно важная роль синапсов в обучении. Сигналы мозга, проходя через них, могут в разной степени усиливаться или ослабляться. Обращает на себя внимание и такой факт.
Мозг новорожденного и мозг взрослого человека содержат примерно одинаковое количество нейронов. Но только мозг взрослого человека отличается упорядоченностью межнейронных синаптических связей.
По-видимому, обучение мозга и есть процесс изменения архитектуры нейронной сети, сопровождаемый настройкой синапсов.
Наиболее емким представляется следующее определение ИНС как адаптивной машины, данное в [6]:
Искусственная нейронная сеть это существенно параллельно распределенный процессор, который обладает способностью к соxраненuю и репрезентацuu опытного знания. Она сходна с мозгом в двух аспектах:
1. Знание приобретается сетью в процессе обучения;
2. Для сохранения знания используются силы межнейронных соединений, называемые также синаптическими весами.
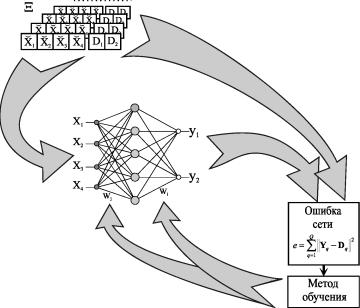
История ИНС начинается в 1943, когда Маккаллок и Питтс предложили модель порогового логического нейрона и показали, что любая функция, которая может быть вычислена на электронно-вычислительной машине, может быть также вычислена сетью нейронов [7]. Сигналы xt, поступающие на вход нейрона, умножаются на весовые коэффициенты wi (синаптические веса). Далее они суммируются, и результирующий сигнал, сдвинутый на величину смещения w0
П
S = Х wixi + щ, (2)
i=1
подается на вход блока, реализующего активационную функцию нейрона.




Общей чертой для всех многослойных перцептронов является прямонаправлен-ность сети, характеризующаяся передачей информации от входного слоя через K скрытых слоев к выходному слою. В стандартной топологии, узел
i в слое k, (k=1,...,K+1) соединяется посредством весов wj^ со всеми j узлами предыдущего слоя k1. Здесь k=0 и k=K+1 обозначают, соответственно, входной и выходной слои.

11).
Вторая вызвана неполнотой информации, предъявленной сети в процессе обучения, из-за ограниченного объема обучающей выборки.
У Розенблатта сила межслойных синаптических связей изменялась в зависимости от того, насколько точно выход перцептрона совпадал с выходным шаблоном, в соответствии со следующим правилом обучения. Веса связей увеличиваются, если выходной сигнал, сформированный принимающим нейроном, слишком слаб, и уменьшаются, если он слишком высокий.
Однако, это простое правило минимизации ошибки применимо только к прямонаправленным сетям без скрытых слоев.
Несколько позже Минский и Пейперт выполнили глубокий анализ вычислительной мощности однослойного перцептрона.
Эффект их совместной книги Персептроны [10], предназначенной внести конструктивный вклад в теорию нейронных сетей, был для многих обескураживающим и привел к утрате интереса к нейронным сетям. Казалось, что если сети не могут реализовать даже XOR-функцию (логическая функция исключающее ИЛИ, получившая с легкой руки авторов [10] статус теста при исследовании сравнительной эффективности тренировоч-
- Шаг 1. Инициализация весов и смещений.
Веса w() и смещения w,(0) во всех слоях задаются случайным образом как маленькие величины, например, в интервале от -1 до +1.
- Шаг 2. Представление нового входного вектора X и соответствующего желаемого выходного вектора D.
- Шаг 3. Прямой проход: расчет фактического выхода.
Шаг 4. Обратный проход: адаптация весов и порогов. Использование рекурсивного алгоритма, начинающегося на выходных узлах и возвращающегося к первому скрытому слою:

Обучающий параметр п обычно выбирается в интервале от 0 до +1.
ных процедур), их вычислительные способности слишком ограничены. Выход из этого положения добавление скрытых слоев с нелинейными нейронами был известен и тогда, однако не было ясности, как настроить веса у такой сети.
Настоящий прогресс был достигнут лишь после того, как Румельхарт, Хинтон и Вильямс в 1986 последовательно переоткрыли Алгоритм Обратного Распространения ошибки (АОР) [11, 12], впервые описанный Вербо-сом в 1974 году [13].
Уместно также вспомнить работы новосибирских ученых [14,15], независимо и одновременно с Румельхартом предложивших очень близкий к АОР Алгоритм Двойственного Функционирования для обучения нейронной сети.Хотя АОР рассеял пессимизм о возможности обучения многослойных сетей, он, тем не менее, не стал инструментом, который позволил бы решить коренной вопрос синтеза нейронных сетей глобальную оптимизацию структуры и параметров сети. Инициализация начальных параметров сети осуществляется здесь случайным образом, а сам АОР, известный в статистике как метод стохастической аппроксимации, является по своей сути не более чем локальным методом и в силу этого не гарантирует окончания процесса обучения в точке глобального экстремума.
Вместе с тем, не вызывает сомнений, что ошибка (4), используемая для оценки качества ИНС, является многоэкстремальной функцией параметров сети, поэтому для поиска ее минимума требуется, соответственно, глобальный метод.
Тем не менее, с появлением АОР интерес к нейронным сетям снова возродился. Нельзя игнорировать и тот факт, что к концу 80-х годов общая ситуация в мире науки существенно изменилась по сравнению с 60-тыми прогресс в разработке персональных компьютеров существенно раздвинул границы численного экспериментирования, началась эра численных методов моделирования.
Искусственные нейронные сети становятся массовым увлечением и через своих поклонников проникают в самые разные научные дисциплины.
Последние 10 лет ознаменовались двумя событиями, имеющими отношение к теме нашего исследования. Первое из них появление RBF-сетей, поддающихся очень простой, не содержащей рекурсии, настройке [16].
Второе применение ГА для тренировки сети произвольной архитектуры, содержащей любые комбинации активационных функций нейронов скрытого слоя [17].
Большое внимание уделялось также доказательству универсальности нейронных сетей для решения задач аппроксимации произвольной функции с любой степенью точности. В [1819] это сделано для сетей перцеп-тронного типа с сигмоидальными активационными функциями, в [20] для RBF-сетей.
Рассмотрим процедуру тренировки RBF-сети (см. Рис.12), осуществляющей аппроксимацию Функтщи, заданной в неявном виде набором шаблонов, как она описана в [16].
Пусть V количество входов сети, H количество нейронов скрытого слоя, Z количество выходов сети.
Предположим, что размер Q набора тренировочных шаблонов Е не слишком велик и что шаблоны размещены достаточно разреженно в пространстве входных сигналов сетиX=(X\,X2, XV).

1. Выберем размер скрытого слоя H равным количеству тренировочных шаблонов Q. Cинаптические веса нейронов скрытого слоя примем равными 1.
2. Разместим центры активационных функций нейронов срытого слоя в точках пространства входных сигналов сети, которые входят в набор тренировочныіх шаблонов Е: cj = X j, j = 1,H.
3. Выберем ширины окон активационных функций нейронов срытого слоя о j, j = 1, H достаточно большими, но так, чтобы они не накла
дывались друг на друга в пространстве входных сигналов сети.
4. Определим веса нейронов выходного слоя сети wiJ-, i=1, Zj = 1, H.
Для этого предъявим сети весь набор тренировочных шаблонов. Выход i-го нейрона выходного слоя для p-го шаблона будет равен:
Yi = wnf (X р, c1)+ wi2f(X pc 2 )+... + wmf(X p,c H )=
= wnf (Xp,X )+ wf2 f (Xp,X2 )+... + wmf (Xp,XH )= Di. Расписав это уравнение для всех выходов сети и всех шаблонов, получим следующее уравнение в матричной форме:
Ф1^ = D, (6)
f1H ^ f2 H
fHH
интерполяционная матрица,
матрица выходных синаптических весов;
матрица выходных шаблонов.
wT =Ф^
(7)
даст нам искомые значения выходных синаптических весов, обеспечивающие прохождение интерполяционной поверхности через тренировочные шаблоны в пространстве выходных сигналов сети.
Ошибка аппроксимации в точках входного пространства, не совпадающих с центрами активационных функций, зависит от того, насколько удачно выбраны ширины окон, и адекватно ли количество тренировочных шаблонов сложности функционального преобразования.
К сожалению, процедура настройки синаптических весов является далеко не единственной и не последней проблемой, встречающейся при обучении сети. Куда как более сложным вопросом остается формирование набора тренировочных шаблонов, адекватно описывающего рассматриваемое функциональное преобразование.
К этой проблеме мы еще вернемся в следующих разделах.
Классические методы синтеза систем управления базируются на хорошо развитом аппарате интегро-дифференциального исчисления, созданном Ньютоном около трехсот лет назад. Нейронные сети представляют собой альтернативное, существующее всего несколько лет, направление в теории автоматического управления, предлагающее иной способ отражения и преобразования действительности, в котором можно обнаружить и сходные, и различные черты с классической парадигмой.
Проникновение дифференциальных уравнений в теорию автоматического регулирования связывают с именами Д. К. Максвелла (18311879) и И. А. Вышнеградского (18311895) [21]. Дело в том, что с момента построения Д. Уаттом паровой машины с центробежным регулятором скорости вращения (1784) и до середины второй половины прошлого века какая-либо теория регулирования просто отсутствовала. Однако, с ростом мощности паровых машин участились аварии, вызванные плохим качеством регулирования.
И вот Максвелл и Вышнеградский почти одновременно и независимо друг от друга взялись за теоретический анализ этой системы. Оба использовали теорию малых колебаний, берущую начало от Ж. Л. Лагранжа.
Записав уравнения Лагранжа для паровой машины и выразив в них фазовые переменные через возмущения относительно некоторых равновесных значений, Максвелл и Вышнеградский линеаризовали уравнения относительно возмущений и исследовали условия устойчивости состояния равновесия.
Так начался первый этап в развитии теории автоматического управления, этап расцвета классических методов анализа. Продолжался он довольно долго до 40-х годов нашего века, но в содержательном отношении не отличался большим разнообразием подходов.
Исследование устойчивости, а также качества переходных процессов продолжали оставаться основными задачами всего этого периода.
Термин нейроуправление впервые появился в работах Вербоса уже в 1976 году, однако решающую роль во внедрении ИНС в сферу управлен-
ческих задач сыграли работы Нарендры с соавторами (1989), в частности,
Итак, в системах управления ИНС могут применяться в виде:
- нейроконтроллеров;
- нейроэмуляторов, имитирующих динамическое поведение объекта управления в целом или описывающих его отдельные характеристики, трудно поддающиеся математическому моделированию (например, фрикционные эффекты и т. п.).
Первое, что мы попытались сделать самостоятельно, был синтез нейроконтроллера на базе трехслойной прямонаправленной сети [23].
В качестве объекта управления мы выбрали инерционное колебательное звено второго порядка с передаточной функцией вида
(8)
T 2 я2 + 2Tqs + Г
а в качестве цели управления подавление колебательности объекта при ступенчатом входном воздействии (значения постоянных коэффициентов к=1; Т= 0,5; q=0,1 в уравнении (8) были подобраны так, чтобы колебательные свойства у объекта были выражены достаточно отчетливо - см. рис. 13).


Для получения такой информации в схеме обучения необходимо предусмотреть обращенный нейроэмулятор объекта, роль которого сводится к преобразованию ошибки на выходе объекта в выходной сигнал на выходе нейроконтроллера, что существенно усложняет процедуру тренировки.

При том, что диапазон изменения каждого из параметров в пространстве т1 был принят от -1 до 1, десятиразрядное кодирование обеспечивало дискретность изменения параметра не хуже 0,002.
После декодирования хромосом в вектора переменных оценивалась способность каждого варианта сети следовать эталонной модели. Проверка осуществлялась путем последовательной подачи на управляющий вход нейроконтроллера единичного положительного, нулевого и единичного отрицательного входного воздействия и вычисления среднеквадратичной ошибки выходной координаты объекта на временном интервале до 10 секунд. Предварительно передаточная функция объекта управления преобразовывалась в систему обыкновенных дифференциальных уравнений в форме Коши
[ x = x2;
\ (9)
[x2 = (- 2Tgx2 - x1 + kU)/4?.
Интегрирование системы осуществлялось с постоянным шагом, равным 0,01 сек. Суммарная ошибка по всем трем переходным процессам принималась в качестве меры неудачности конструкции и использовалась далее в качестве количественного индекса для ранжирования особей в популяции.
Кривые переходных процессов для лучшего варианта из популяции на различных этапах поиска представлены на рис. 16.

Лучшие из демонстрируемых популяцией нейроконтроллеров переходные процессы на выходе объекта управления в различные моменты работы ГА (задание единичная ступенька): кривая 1 начальная популяция, 2 после 2000 поколений, 3 после 4000 поколений, 4 после 5000 поколений.
Как видно из этого рисунка, по мере работы алгоритма решения непрерывно улучшаются. Вектор переменных, найденный к 5000 поколению, обеспечивает вполне удовлетворительное решение поставленной задачи.
Рис. 17 иллюстрирует поведение объекта не только на тренировочных шаблонах, но и при промежуточных значениях амплитуды входного зада-

18).

19).
На этот раз для контроллера опять была выбрана трехслойная сеть 3-10-1, т. е. с количеством нейронов в скрытом слое равным 10. Для определения пригодности сети на ее вход подавался фиксированный спектр гармонических колебаний различной амплитуды (в диапазоне 0,1-1) с частотами 0,16; 0,48; 0,80; 1,11 и 1,59 Гц.
Интегральная ошибка по всем тестовым переходным процессам, продолжительность которых, как и ранее, составляла 10 секунд, принималась в качестве меры успешности управления.
Результаты синтеза оказались удачными. Контроллер, параметры которого представлены в Приложении 1, справлялся с возложенными на него задачами.
Фактическая АЧХ нейросетевой системы управления представлена на рис. 19. Она построена уже на непрерывном спектре частот, включающем частоты тренировочных сигналов.
По-видимому, из-за недостаточного размера скрытого слоя сети, синтезированная АЧХ на участке 0,61 Гц значительно отличается от эталонной. Однако в общем, полученные результаты свидетельствует, что способность сети к обобщению может использоваться и при синтезе нейроконтроллера в частотной области.
